








 38. (Julio 2012) Estadística en la musicología I
38. (Julio 2012) Estadística en la musicología I |
 |
 |
 |
| Escrito por Paco Gómez Martín (Universidad Politécnica de Madrid) | |||||||||||||||||||||||||||
| Miércoles 25 de Julio de 2012 | |||||||||||||||||||||||||||
|
1. Introducción Este artículo inaugura una serie que se titula Estadística en la musicología. El título de la serie puede parecer una provocación, pero no es así, y ello merece una explicación. La musicología -en su definición más amplia- es el estudio de la música. El musicólogo Richard Parncutt [Par07] da una definición de musicología que se inspira en la entrada correspondiente del prestigioso diccionario The New Grove Dictionary of Music and Musicians [SSE01] (nuestra traducción, sus cursivas): “Sugiere (el diccionario) que la musicología hoy comprende todas las disciplinas que estudian toda la música en todas sus manifestaciones y en todos sus contextos, sean estos, físicos, acústicos, digitales, multimedias, sociales, sociológicos, culturales, históricos, geográficos, etnológicos, psicológicos, médicos, pedagógicos, terapéuticos, o en relación a cualquier otra disciplina o contexto musicalmente relevante”. A pesar de que la edición del diccionario es de 2001 y el artículo de Parncutt de 2004 todavía echo de menos disciplinas que se han ocupado muy activamente de la música como objeto de estudio, como por ejemplo: las neurociencias, los estudios (auto-)etnográficos, los estudios de género, la estética, la semiótica, la antropología, pero también las ciencias de la computación1 y, lo que es pertinente a esta columna, las matemáticas. Por su longitud y amplitud, la lista anterior puede intimidar un poco, pero hay que advertir que ni todos los enfoques ni todos los métodos son válidos en musicología. De hecho, se pueden encontrar casos en que la aplicación de ciertos métodos ha producido extralimitaciones conceptuales. Sin embargo, esta rica mezcla de disciplinas aplicadas al estudio de la música no se formó sino hace relativamente poco tiempo, unas cuatro o cinco décadas aproximadamente. Al principio, la musicología era simplemente el estudio de la música occidental, principalmente con métodos históricos. Como disciplina más o menos independiente se encontraba la musicología comparada, que más tarde devino en la etnomusicología. Poco a poco el fenómeno musical se fue investigando en un sentido más amplio y otras disciplinas se incorporaron a su estudio, si bien esas disciplinas pertenecían fundamentalmente al campo de las humanidades. Se estudiaba la música desde la perspectiva histórica, literaria, filosófica o del análisis musical occidental. Poco a poco se empezó a aceptar que había otras músicas, con sus propias estructuras, estilos e instrumentos. Más tarde se unieron otras disciplinas, pero destacan dos que han dado un fuerte impulso a la investigación y señalado ángulos de estudio necesarios para la consolidación de una musicología moderna: la psicología y las ciencias de la computación. La música tiene una componente cognitiva muy importante que hasta finales de los años sesenta había sido casi ignorada por completa. Con trabajos pioneros como los de Diana Deutch se inauguró una intensa era de investigación de los mecanismos perceptuales y cognitivos de la música; véase [RB03] para una excelente visión del campo. Respecto a las ciencias de la computación, los modelos computacionales se hicieron totalmente necesarios para la comprensión de la música así como para su procesamiento. Por ejemplo, Jackendoff y Lerdahl [LJ83], inspirándose en las teorías de la gramática generativa de Chomsky, desarrollan una teoría generativa de la música que identifica estructuras y propone reglas de transformación. Según su metodología, la musicología se ha clasificado en cualitativa, cuantitativa y etnográfica2. La musicología cualitativa usa métodos cualitativos (entrevistas, observaciones, análisis de documentos, archivística, interpretación de textos, estudio de casos, etc.). Estos métodos provienen principalmente de las humanidades. Los métodos etnográficos consisten en la investigación vía la integración del investigador en el contexto de la investigación; si el investigador mismo es el protagonista se habla entonces de métodos autoetnográficos (por ejemplo, el musicólogo que entra en una formación musical de una cultura dada para investigarla desde dentro y no como observador externo). Dentro de los métodos (auto-)etnográficos se encuentra la redacción de diarios, los cuadernos de campo, las grabaciones en audio y vídeo, así como técnicas específicas de análisis. Por último, está la musicología más reciente, la cuantitativa, que en buena medida es computacional. Esta musicología reconoce que la música tiene aspectos cuantificables y modelizables computacionalmente y busca construir modelos, reconocer estructuras y producir algoritmos que permitan procesar la música para su mejor comprensión y análisis. Un ejemplo sencillo de este tipo de musicología lo tenemos en el procesamiento automático de música. Con los nuevos medios de representación y almacenamiento, podemos disponer de corpus de música de varios cientos de horas. Buscar una característica común -digamos un cierto patrón melódico-, a mano (a oído, más bien), puede llevar al menos tantas horas como el corpus mismo. Un procesamiento adecuado del corpus puede localizar ese patrón en cuestión de minutos, y darnos datos de los que sacar información valiosa. Incluso hoy en día, la musicología cuantitativa no goza de la aceptación incondicional de toda la comunidad de estudiosos de la música. En este artículo, como decía más arriba, vamos a ver unas cuantas aplicaciones de la estadística a la musicología. La serie está pensada más para músicos que para matemáticos y en la entrega de hoy exploraremos las posibilidades de la estadística descriptiva. El resto de este artículo sigue la presentación del excelente libro Statistics in Musicology [Ber04], de Jan Beran, capítulo uno. Recomiendo vivamente la lectura de este libro. 2. Estadística descriptiva El objetivo de la estadística descriptiva es encontrar una serie de medidas que sean representativas de un conjunto de datos numéricos. Normalmente, el conjunto de datos es muy grande y la serie de medidas es pequeña. El conjunto de datos recibe el nombre de muestra. Las medidas se clasifican en tres grandes grupos:
Para dar un ejemplo claro de esta clasificación, proponemos al lector, al músico en especial, la siguiente cuestión: dado un conjunto de n números reales S = {x1,x2,…,xn}, la muestra, ¿cómo elegir un número μ que lo represente en algún sentido? Una primera idea sería tomar las distancias de μ a todos los puntos de S, esto es, la suma de los errores cometidos al sustituir los puntos de S por el valor μ, y dividirlo por el número de puntos. Dividimos por el número de puntos para que este no influya en el error final. Entonces, el error cometido en la sustitución es una función E(μ), que se escribe como:
(El símbolo ∑ significa hacer la suma desde i=1 hasta n de la expresión que sigue a continuación; se llama sumatorio). El valor que buscamos y que resume el conjunto S en uno solo es aquel que minimice esta función E(μ), que haga el error lo más pequeño posible. Encontrar el mínimo de esta función vía las derivadas no es factible, ya que el valor absoluto no es derivable (esta es una razón técnica que los músicos pueden saltarse sin ningún complejo de culpabilidad). En su lugar se usa la siguiente función E(μ):
Calculemos el valor mínimo de E(μ) con las derivadas:
Como E′′(μ) = 2n para todo μ, el valor que hemos obtenido es, en efecto, un mínimo para E(μ). Obsérvese que esta función da la suma de los cuadrados de los errores al sustituir los puntos de S por el único valor μ. Este valor recibe el nombre de media muestral y se escribe El valor del error en μ =
y recibe el nombre de varianza; volveremos a ella enseguida. Como medida de centralización, la media muestral tiene el inconveniente de que es muy sensible a datos anómalos. Pensemos en el conjunto {5,5,5,5,5,5}; claramente, su media será μ = 5. Sin embargo, si por error uno de los cincos se transforma en un cero, entonces la nueva media es μ = 25∕6 ≈ 4′1666. Las dos siguientes medidas sirven para representar el conjunto y son más robustas ante datos anómalos:
Una vez establecidas las medidas de centralización, la pregunta más natural es cuándo son representativas esas medidas. Ciertamente, no siempre son representativas, y de ahí la posibilidad de manipulación de los datos. Las medidas de dispersión proporcionan criterios para determinar cuándo las medidas de centralización son representativas. La primera medida que presentamos es la varianza, vista ya anteriormente. Por razones técnicas (que se pueden encontrar en el capítulo 8 de [RES00]), la varianza que se usa en estadística descriptiva se llama varianza muestral s2 y su definición es:
La varianza muestral tiene el inconveniente de que está no está expresada en las unidades de los números x1,x2,…,xn. Por ello, se define la desviación típica s, que es sencillamente + Otras medidas de dispersión son:
Los valor anómalos se definen como aquellos que están fuera del intervalo
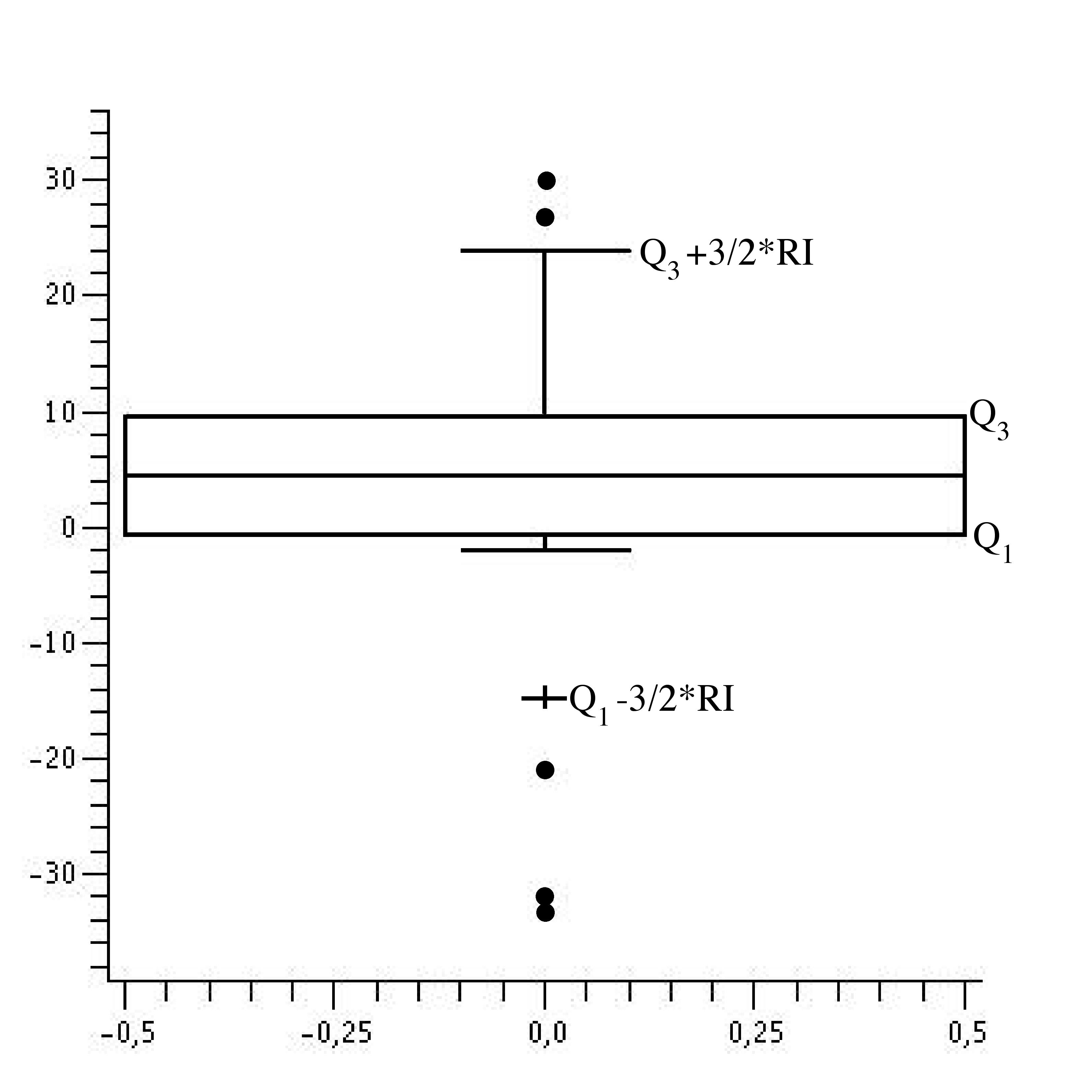
Una manera gráfica de ver los valores anómalos es construir el diagrama de caja. Se construye una caja cuyo límite inferior es Q1 y cuyo límite superior es Q3; en el medio de la caja se marca la mediana M. Después se dibujan sendas patas, que van desde la caja hasta el valor no anómalos más alejados, como se indica en la figura 1. Los datos anómalos son los círculos negros fuera de la patas de la caja.
Por último, vamos a ver el coeficiente de asimetría, que está definido por la fórmula:
y que indica la simetría de los datos respecto a la media. Si m3 > 0, entonces los datos están más concentrados a la derecha de la media muestral; si m3 < 0, lo están a la derecha; y si m3 = 0, son perfectamente simétricos respecto a la medida muestral. Dejamos aquí este breve repaso de estadística descriptiva, repaso que nos servirá para ilustrar unas cuantas aplicaciones en musicología cuantitativa. Para profundizar más en la estadística descriptiva, véase [POD11]. 3. Aplicación a espacios musicales Para ilustrar el uso de la estadística descriptiva, tomaremos la obra Träumerei, de Robert Schumann, una exquisita pieza. Abajo tenemos un vídeo con la interpretación de esta pieza por la pianista Valentina Lisitsa.
La partitura de la pieza se puede ver en la figura 2.
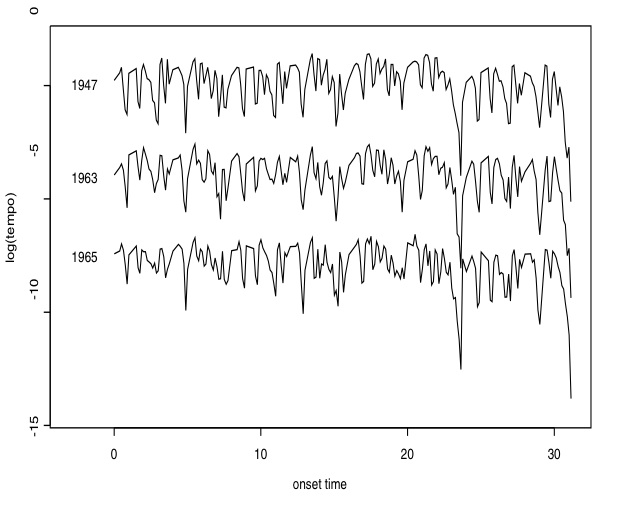
Vamos a analizar las curvas de tempo de varias interpretaciones de esta pieza. En general, los cambios de tempo suelen locales más que globales y se usan como medio para dotar de expresividad a la interpretación. En la figura 3 se muestran tres interpretaciones del pianista Vladimir Horowitz. Las curvas se parecen bastante entre sí cuando se consideran en su totalidad, pero se aprecian cambios a nivel local, cambios que se pueden estudiar mediante técnicas estadísticas. Las curvas de tempo se han tomado en escala logarítmica. Típicamente el tempo se mide en pulsos por minuto y puede variar desde 20 pulsos por minuto, Larghissimo, hasta 240 pulsos por minuto, Prestissimo con fuoco. Tal rango de valores se representa mejor bajo una escala logarítmica, esto es, tomando el logaritmo del tempo. Las curvas de tempo se han obtenido muestreando las grabaciones a intervalos muy pequeños e interpolando los puntos obtenidos.
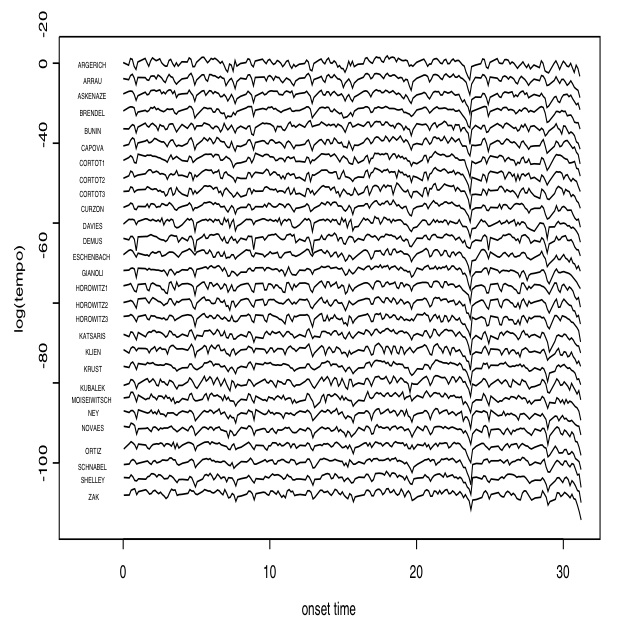
Podría esperarse que el tempo fuera más o menos constante dentro de una pieza, pero estas curvas muestran que no es así. Todas estas microvariaciones dan expresividad a la interpretación. Vamos a llevar un análisis un poco más complejo. Consideremos las 28 curvas de tempo de la figura 4; corresponden a 28 interpretaciones de Träumerei de los siguientes pianistas: Martha Argerich (antes de 1983), Claudio Arrau (1974), Vladimir Ashkenazy (1987), Alfred Brendel (antes de 1980), Stanislav Bunin (1988), Sylvia Capova (antes de 1987), Alfred Cortot (1935, 1947 y 1953), Cli?ord Curzon (alrededor de 1955), Fanny Davies (1929), Jörg Demus (alrededor de 1960), Christoph Eschenbach (antes de 1966), Reine Gianoli (1974), Vladimir Horowitz (1947, antes de 1963 y 1965), Cyprien Katsaris (1980), Walter Klien (fecha desconocida), André Krust (sobre 1960), Antonin Kubalek (1988), Benno Moisewitsch (sobre 1950), Elly Ney (sobre 1935), Guiomar Novaes (antes de 1954), Cristina Ortiz (antes de 1988), Artur Schnabel (1947), Howard Shelley (antes de 1990), Yakov Zak (sobre 1960).
Desde un punto de vista de la forma, Träumerei se puede dividir en cuatro secciones, que, siguiendo la notación de [Ber04], llamaremos A, A′, B y A′′. La sección A expone el material temático, en la sección A′ ese material temático se desarrolla, a continuación viene una sección, la B, que contrasta, y finalmente la pieza acaba con una sección que recapitula con el material de la sección A. Para las 28 interpretaciones, en la figura 5 se ha calculado la media muestral
Se puede realizar un análisis más profundo añadiendo más medidas estadísticas. De nuevo, consúltese el capítulo 2 de [Ber04] para información más detallada.
Notas: 1 Evito aquí el término informática. Se podría interpretar como la programación de aplicaciones cuando, en realidad, me estoy refiriendo a la creación de modelos computacionales de la música. 2 También se encuentra la expresión de estudios performativos de la música, que tiene difícil traducción en castellano. Hemos preferido llamarlos estudios etnográficos.
Bibliografía: [Ber04] J. Beran. Statistics in Musicology. Chapman & Hall/CRC, 2004. [LJ83] F. Lerdahl and R. Jackendoff. A Generative Theory of Tonal Music. MIT Press, Cambridge, Massachussetts, 1983. [Par07] Richard Parncutt. Systematic musicology and the history and future of western musical scholarship. Journal of Interdisciplinary Music Studies, 1:1–32, 2007. [POD11] R. Peck, C. Olsen, and J.L. Devore. Introduction to Statistics and Data Analysis. Brooks/Cole, 2011. [RB03] R. E. Radocy and D. J. Boyle. Psychological Foundations of Musical Behaviors. Charles C. Thomas, Springfield, Ill., 2003. [RES00] V. Rohatgi and A. K. Ehsanes Saleh. An Introduction to Probability and Statistics. Wiley-Interscience, 2000. [SSE01] John Tyrrell (Editor) Stanley Sadie (Editor). The New Grove Dictionary of Music and Musicians. Akal, 2001. |
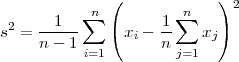


![]()
| © Real Sociedad Matemática Española. Aviso legal. Desarrollo web |