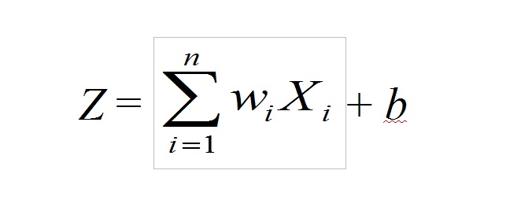Las matemáticas que se esconden detrás de la seguridad del coche autónomo
Las matemáticas que se esconden detrás de la seguridad del coche autónomo
|
Las matemáticas que se esconden detrás de la seguridad del coche autónomo |
|
|
ABC, 12 de Noviembre de 2018 ¿Qué hay detrás de la tecnología que hace que se frene un coche sin que una persona se lo diga?
Desde que Nicolas-Joseph Cugnot y posteriormente Karl Benz idearan los primeros vehículos automóviles, la evolución de este invento ha sido incuestionable. Y las matemáticas cada vez han tenido más que decir. Más aún en la era del coche autónomo, un vehículo que promete, en un futuro no muy lejano (ya lo hacen de hecho), manejarlo sin necesidad de que hagamos absolutamente nada, sólo dejarnos llevar y disfrutar del viaje. El asunto provoca no pocos recelos. No obstante, cada vez más marcas anuncian nuevos e interesantes sistemas de seguridad a los que no hacemos demasiados ascos, y que no son más que el preludio de tecnologías asombrosas. Aunque, para abrir boca de momento, en equipamiento opcional (el negocio es el negocio), los vehículos ofertan cada vez más sistemas de detección del entorno. Gracias a ellos, el coche es capaz de frenar automáticamente ante el riesgo de un atropello del que el conductor no se ha percatado, evitar una colisión, detenerse antes de abollar a los coches adyacentes en un aparcamiento, etc. En los anuncios se ilustra de un modo espectacular, y así es, no nos mienten en nada (salvo en algunos flecos por pulir aún, pero son fiables en un 80% de las situaciones aproximadamente). Sin embargo, no nos dicen cómo lo consiguen. Y eso es lo que se va a tratar aquí, la parte matemática. Primero, echemos un vistazo a las prestaciones que deseamos conseguir. Necesitamos que el sistema detecte y distinga diferentes objetos e indicaciones: peatones, ciclistas, otros vehículos, señales de tráfico y su significado, los márgenes de la calzada, actualización del contexto en tiempo real… Es evidente que para captar lo que sucede en la calzada, el vehículo debe tener incorporado una o varias cámaras de la mayor resolución posible. Además de un objetivo gran angular para que pueda visualizar ángulos muertos para nosotros. Estas cámaras deben situarse en lugares con la mayor visibilidad posible sin molestar (suelen estar en la parte alta del parabrisas y centradas delante del espejo retrovisor), y captan varios cientos de imágenes que mandan al ordenador del automóvil. Todas esas imágenes deben ser analizadsa e interpretadas. Una opción, la más utilizada hasta ahora, era la del GPS o de los sensores de proximidad. Otra posibilidad distinta son los algoritmos, esencialmente de dos tipos: de visión artificial y de machine learning (aprendizaje automático).
En la imagen, información registrada por el software en plena conducción, detectando otros vehículos y señales de limitación de velocidad. A partir de ella, adecua la velocidad y mantiene la distancia de nuestro vehículo Algoritmos de «machine learning» Como su nombre indica, son procesos mediante los cuales la máquina aprende por sí sola, sin ser explícitamente programada. Abarcan muchas técnicas y algoritmos, aunque básicamente pueden clasificarse en dos tipos, en función de qué pretenden aprender y de cómo pretenden hacerlo. A su vez, según el tipo de problema al que se enfrenten, pueden dividirse en algoritmos de regresión y algoritmos de clasificación. Los primeros utilizan datos continuos (por ejemplo, una editorial para pronosticar el número de libros que se pueden vender en el mes de noviembre emplea datos independientes entre sí como las ventas hechas en los meses anteriores, en varias ciudades, etc.), mientras que los segundos tratan de predecir a qué clase pertenece un conjunto de datos. Según la forma de aprender, los algoritmos machine learning se dividen en supervisados y no supervisados. La diferencia es evidente a partir de su nombre: los primeros necesitan un experto que los oriente, por lo que, en la fase inicial, todos los datos deben estar correcta y perfectamente etiquetados. En los segundos, el algoritmo establece la clasificación de datos por su cuenta, básicamente comparando, buscando similitudes entre imágenes, por ejemplo. De cada uno de estos tipos, hay una amplia gama de algoritmos. Tras esta panorámica general, centrémonos en el tema del que estamos hablando, eligiendo un algoritmo de clasificación supervisada. Este tipo se utiliza en situaciones que requieren, por ejemplo, clasificar imágenes, reconocimiento de escritura, reconocimiento del habla, descubrimiento de drogas, cualquier circunstancia en la que se necesite separar datos en clases previamente definidas. Y entre los algoritmos de esta clase, describiremos las conocidas como redes neuronales artificiales. Red Neuronal Imitando el funcionamiento del cerebro humano, las redes neuronales artificiales se basan en el manejo de un sistema de células elementales, llamadas por analogía neuronas, que se interconectan entre sí en varias capas o niveles, y de modo que los enlaces entre ellas pueden incrementar o inhibir el estado de activación de las neuronas adyacentes. En este caso los estímulos nerviosos empleados son funciones matemáticas.
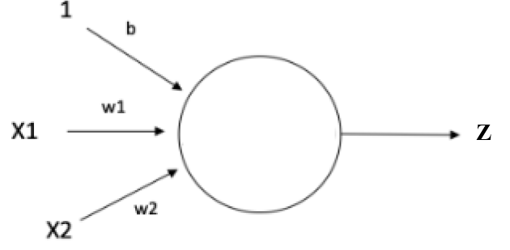
Tal y como se muestra en la figura superior, cada neurona recibe del exterior o de otras neuronas una serie de estímulos Xi. A cada uno de ellos se le asocia un peso wi (un valor numérico) de acuerdo a la relevancia que los demos. Con esos valores se calcula una suma ponderada a la que se le puede además añadir otros valores independientes b. No me digan que no se entiende mucho mejor, y de un simple vistazo, mediante esta expresión:
(En el caso de la imagen anterior, sería Z = w1 X1 + w2 X2 + b; no es demasiado complicado). Posteriormente, a este valor Z se le suele aplicar una función de activación σ, cuyo objeto es generalmente eliminar la linealidad de la red (los actos de nuestra vida, los fenómenos naturales, etc., no se comportan de manera lineal casi nunca: el simple lanzamiento de una piedra describe una trayectoria parabólica, por poner un ejemplo elemental, o las ondas descritas en el agua por esa misma piedra son circulares). Esas expresiones son funciones matemáticas (funciones salto, logística, arco tangente, tangente hiperbólica, etc.). Cada una tiene sus ventajas e inconvenientes, dependiendo del problema que se pretenda abordar, aunque lo usual es realizar pruebas con varias de estas funciones hasta obtener los resultados más satisfactorios al problema que se está modelizando. Una vez aplicada esa función de activación, la neurona seguirá finalmente la expresión: Y = σ(Z). Se han ideado tres tipos básicos de este tipo de «neuronas matemáticas»: las neuronas de entrada, que son las encargadas de proporcionar información del exterior de la red al resto de neuronas, y no realizan ningún cálculo; las neuronas ocultas, que no tienen conexión directa con el exterior, realizan los cálculos y se encargan de enviar la información desde la entrada a la salida; y las neuronas de salida, que dan información al exterior de la red, y también efectúan cálculos. Seguramente el lector se pregunte sobre cómo se eligen esos pesos wi indicados anteriormente. Inicialmente podemos poner unos valores cualesquiera porque, a continuación, se entra en una fase de entrenamiento del modelo. Es decir, los valores adecuados los vamos a ir obteniendo a base de experimentar y confrontar los datos obtenidos de la realidad y del modelo que hemos construido, y se irán calculando ellos solos, iterativamente. ¿Y esto cómo se hace? Nuevamente las matemáticas nos sacan del apuro. Se toma una nueva función (elegida de entre un muestrario conocido) llamada función de pérdida que nos va a calcular el error que estamos cometiendo. Se prueban varias funciones de pérdida y se considera una media de todas las que probemos, obteniendo una nueva función, la función de coste. Por supuesto todo esto lo hace el ordenador y nuestra función es interpretar los datos y cambiar los parámetros después de analizar la situación (que no se hace a nuestro libre albedrio; de nuevo son las matemáticas las que nos aconsejan qué decisiones tomar). Además, hay software disponible que nos facilita también la obtención de los parámetros que necesitamos, software que nuevamente son algoritmos matemáticos implementados para que funcionen en un ordenador. La última fase es la activación de la neurona, de cada una de las neuronas que componen la red. A veces no es conveniente activar alguna, otras veces sí; depende de cada situación. Como en nuestro cerebro, no activamos los mismos mecanismos, sino que lo hacemos de acuerdo a la situación. Como hemos indicado antes, estos objetos tratan de reproducir lo mejor posible la más perfecta de las máquinas, el cerebro humano. Pero la cosa no acaba aquí. Establecido el funcionamiento de las neuronas, hay que decidir cómo interaccionan entre sí. Lo normal es agruparlas en varias capas, y estas capas son las que se relacionan unas con otras. Hay muchos modelos (los más utilizados son los convolucionales, que surgieron precisamente estudiando la visión artificial). Finalmente, todas esas capas deben integrarse en una arquitectura adecuada que emplee todas esas conexiones para poder aplicarlas en la resolución de problemas reales. Esta es la parte más informática, aquí las matemáticas pintan menos (aunque no desaparecen del todo). Bastante han hecho ya: han conformado el «cerebro». No obstante, volverán a aparecer en la parte del diagnóstico y corrección de errores.
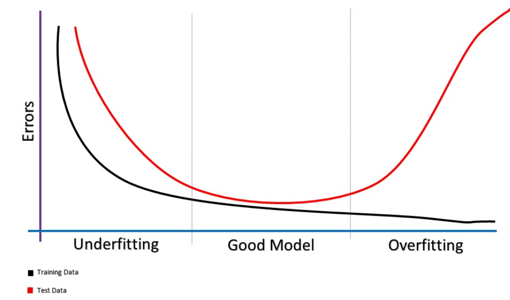
La imagen superior muestra cómo se modifica el error tanto del conjunto de entrenamiento como del conjunto de pruebas. En el eje horizontal (el de abscisas, el OX) se indica el número de iteraciones que realiza la red durante el aprendizaje. En el vertical (el de ordenadas, el OY) muestra el error que comete cada conjunto. Observamos que al inicio del entrenamiento los dos errores están muy altos. Acertar aquí es pura chiripa. A medida que se va entrenando la red con más ejemplos, los errores van disminuyendo. El error sobre el conjunto de entrenamiento (la curva negra, el training data) disminuye más rápido, obviamente, porque son los datos sobre los que está aprendiendo la red. La zona ideal es aquella en la que vemos más cercanas las curvas, la banda central, en la que hemos encontrado un buen modelo. A continuación, paradójicamente, llega un punto en el que, a pesar de aumentar el número de iteraciones, el error de nuestro modelo se dispara. Es la típica situación en la que la red tiene un problema de varianza. Gráficas de este tipo nos permiten detectar qué tipo de problemas podemos encontrarnos, y tras su análisis, intentar corregirlos. Quizá al lector le parezca todo esto muy complicado, correspondiente al trabajo de expertos ingenieros y programadores. Nada más lejos de la realidad. Gran parte de la información descrita es de un trabajo fin de grado de un alumno de informática que tuve que evaluar el curso pasado y que me ha parecido interesante. Y las matemáticas de su plan de estudios se reducen a cuatro asignaturas dentro de un grado de tres años. No son muchas, ni muy elevadas (aunque los alumnos piensen lo contrario, esa es otra historia). Pero fíjense el juego que dan. Un poco de historia Los algoritmos machine learning tienen ya su historia, aunque es ahora, con la actual potencia de los ordenadores y microprocesadores cuando se les empieza a sacar mayor partido. En 1943, el neurólogo Warren McCulloch, y el matemático Walter Pitts, modelizaron una primitiva Red Neuronal Artificial mediante circuitos eléctricos. En 1950, el ingeniero eléctrico Nathananial Rochester intentó recrear una red neuronal en IBM, pero no tuvo éxito. No fue hasta 1952 cuando Arthur Samuel, otro de los pioneros en Inteligencia Artificial, desarrolló un programa capaz de jugar a las damas, que aprendiera y mejorara su estrategia después de cada partida. Desde entonces el avance en este campo ha ido en aumento. Podríamos llenar varios volúmenes con la gran cantidad de modelos que se han desarrollado desde entonces. Pondremos únicamente dos ejemplos:
Uno de los hitos más destacados de los algoritmos Machine Learning, por el eco mediático producido, tuvo lugar en 1997, cuando Deep Blue derrota al gran maestro de ajedrez Garri Kaspárov. Treinta años después, estas técnicas se perfeccionan y logran una hazaña mayor: vencer al mejor jugador de Go, el juego de mesa más complejo que existe (el número de partidas posibles excede varias veces el número de átomos del universo observable). Un par de años después, el algoritmo AlphaGo Zero, también con técnicas de redes neuronales, fue capaz jugar al Go sin necesidad de la intervención humana, y al cabo de veinte días jugando contra ella misma alcanza un nivel que logró derrotar a 60 jugadores expertos y al campeón mundial en tres partidas. El nuevo algoritmo, evolucionado del inicial, es considerado el mejor jugador de la historia de este juego. Este algoritmo marca un antes y un después en este tipo de técnicas, ya que la intervención humana en el proceso fue muy limitada: le bastaron las reglas del juego para entrenarse de manera autónoma. Imagínense, con la gran cantidad de datos que los dispositivos actuales pueden almacenar y la potencia y capacidad de los equipos (recordemos esa palabra que tanto se menciona, el Big Data), este tipo de modelos que aprenden autónomamente van a convertirse con toda seguridad en elementos que van a revolucionar las tecnologías, y seguramente nuestras vidas. No tienen más que acudir a dos ejemplos de robots: Sophia, diseñado por Hanson Robotics (el primer robot declarado ciudadano de la historia) y Michihito Matsuda, desarrollado por Norio Murakami (ex-empleado de Google) y Tetsuzo Matsuda (vicepresidente de Softbank), robot que fue presentado el 15 de marzo del presente 2018 a la alcaldía de Tama, un distrito de Tokio (obtuvo la tercera posición con más de cuatro mil votos). Así que, acabo con una frase, atribuida a Pitágoras, pero vaya usted a saber de quién es. En cualquier caso, es absolutamente certera y que la comparto totalmente, además de dedicarla (con cariño) a los machacones del «para qué sirven las matemáticas»: «Las matemáticas no pueden resolverlo todo, pero sin ellas no puede hacerse nada». Alfonso J. Población Sáez es profesor de la Universidad de Valladolid y miembro de la Comisión de divulgación de la RSME. El ABCDARIO DE LAS MATEMÁTICAS es una sección que surge de la colaboración con la Comisión de Divulgación de la Real Sociedad Matemática Española (RSME) |